
以下源码分析基于go1.14.13版本
一、Map底层原理
Golang的Map数据结构底层原理是哈希桶,解决冲突Hash的冲突使用的是开散列,也就是将具有相同关键码的元素用单链表连接起来
哈希桶的原理:哈希桶使用顺序表来存放Key链表的头结点,每一个Key有对应的链表。
如有以下数字[1,6,8,11,13,14],hash(key)=value%5,存储在hash表如下图:
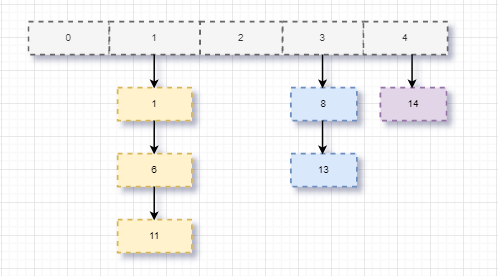
而Golang定义的哈希桶又有不同,我们在源码分析中会继续进行讲解
二、举个小栗子
该例子就是对map进行初始化、插入、查询、遍历、删除等简单操作
1 | func main() { |
看汇编代码,对应链接的源码接口(也即CALL命令后runtime.XXX)
1 | # 注:只截取部分关键汇编代码 |
三、源码分析
1、Map结构体
1 | // A header for a Go map. |
一个map的哈希桶数据结构如下。可以看到与普通的hash桶不一样的是,桶链里面的溢出桶(overflow)可以装固定大小的K-V值。且桶的大小是2的B次方,B值是由申请的map大小值和后续的扩容决定的。
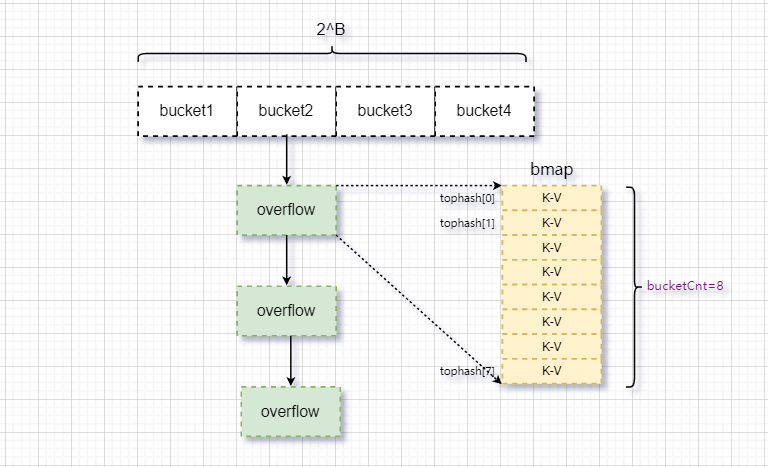
2、初始化
初始化分2种情况
make的时候不指定map的size。如:make(map[int]int)
创建map时,当没有指定size大小或size为0时,不会创建哈希桶,会在插入元素时创建,避免只申请不使用导致的效率和内存浪费make的时候指定map的size。如:make(map[int]int,100)
这个时候会按照提供的元素个数,找一个可以放得下这么多元素的 B 值,也就是确定bucket的个数。bucket的大小是2的整数(B)次幂,按照前人总结哈希桶大小约= size/ 6.5
1 | // 没有指定map的大小,初始化一个hmap结构体,返回一个hmap类型 |
3、查找
查找流程:我们暂且B值设为4,则共有2^4=16个bucket。
计算key对应的hash值
取hash值的后4(B)位,这个值指定目标值所在的bucket的位置(共16个)
取hash值的前8位,这个值指定的是目标值在某个overflow的哪个格子(共8个)
找到确定位置,返回Key值对应的Value值。
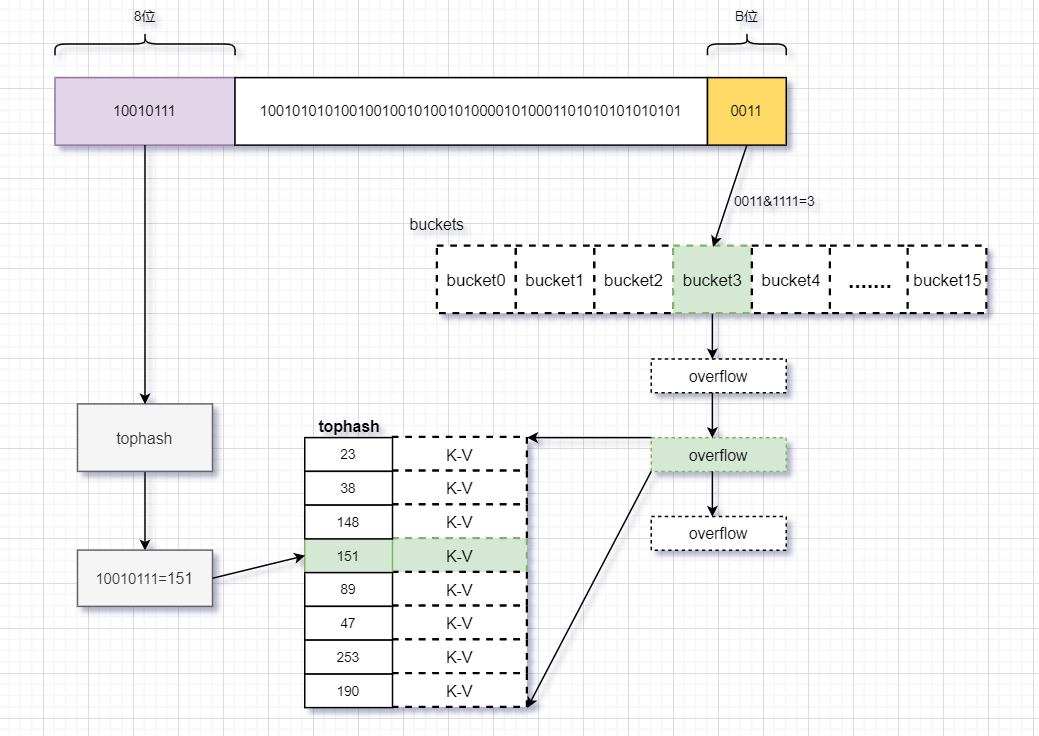
1 | // 查询Key对应的value值 |
4、插入(更新)
理解了查询的流程,插入的流程很类似了。
插入流程:
计算key的hash值,并使用后B位计算属于哪个bucket
若当前空为空桶,则创建一个bucket;bucket不够,扩展bucket
遍历对应bucket的桶链,使用高8位hash看该key值是否存在,若存在,则进行更新操作
若不存在,则找到空位进行插入
若已有的bucket没有找到空位,则创建新的bucket进行存储
期间若达到hash扩展的条件,则进行hash扩张,再进行插入
注意插入函数只将KEY的值插入,返回存储value值对应的内存地址。汇编来进行将value值存储在对应的内存空间。
如下图可以表示插入的流程:
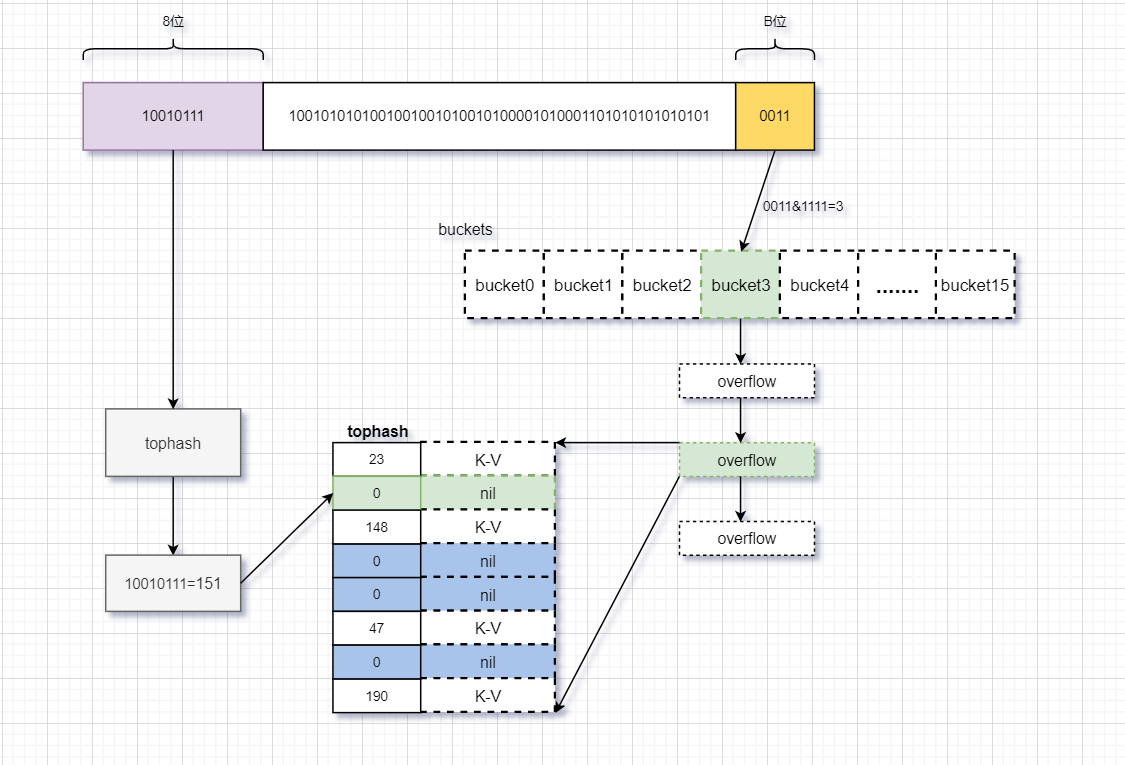
1 | // 插入(更新) |
5、删除
删除流程:
- 计算key对应的hash值
- 取hash值的后4(B)位,这个值指定目标值所在的bucket的位置(共16个)
- 取hash值的前8位,这个值指定的是目标值在某个overflow的哪个格子(共8个)
- 找到确定位置。若key值是指针,则置空;否则
1 | // 删除某个key对应的值 |
6、扩容
扩容发生在插入的mapassign中:
触发扩容的2种情况
1、几乎所有桶要满了,如果插入新元素,大概率挂在overflow上。也即平均每个bucket存储的键值对达到6.5个
解决办法:增量扩容。将B+1,也就是扩张bucket 1倍
2、overflow的桶太多了
bucket 总数 < 2 ^ 15 时
overflow 的 bucket 总数 >= bucket 的总数,即认为overflow 的桶太多了bucket 总数 >= 2 ^ 15 时
overflow 的 bucket >= 2 ^ 15 时,即认为溢出桶太多了。
因为我们对 map 一边插入,一边删除,会导致其中很多桶出现空洞,这样使得 bucket 使用率不高,值存储得比较稀疏。在查找时效率会下降。
解决办法:等量扩容。通过移动 bucket 内容,使其倾向于紧密排列从而提高 bucket 利用率
1 | func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer { |
1 | // hash扩容 |
下面详细说明2种扩容的方法:
1、增量扩容
oldbuckets指向当前的bucket
开始扩容,B=B+1。
buckets指向新申请的bucket
将老数据迁移到新指向的bucket
删除oldbuckets指向的bucket
场景如下:
1) 触发增量扩张,只有一个bucket,且overflow装了7个元素(B=1)
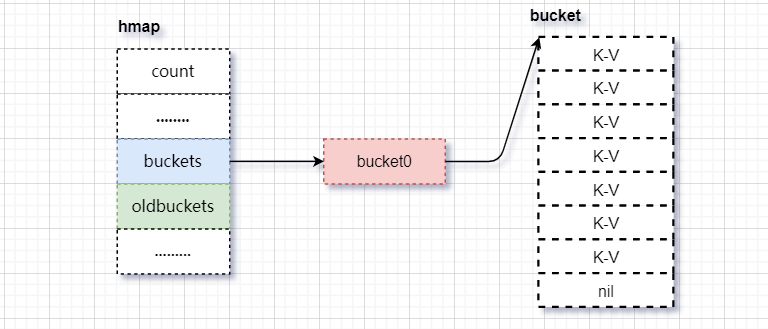
2)扩张bucket。B=2,oldbuckets指向当前的bucket。buckets指向新申请的bucket
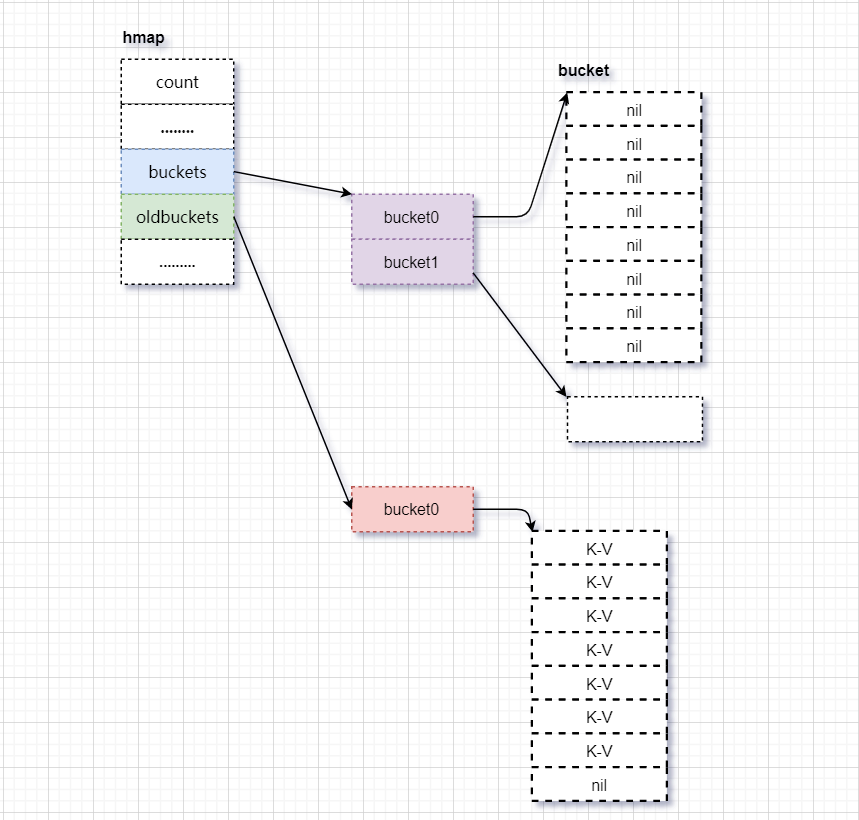
3)数据迁移。删除oldbuckets指向当前的bucket
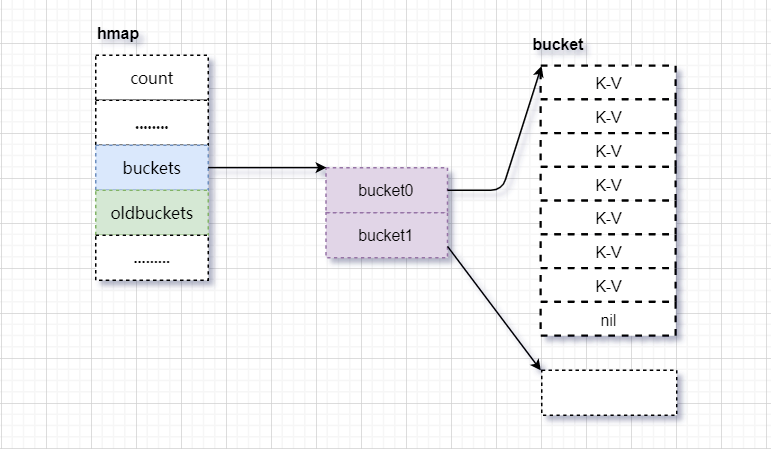
2、等量扩容
也就是将松散的键值对重新排列一次,以使bucket的使用率更高,进而保证更快的存取。将空的格子放在一起
三、思考
1、是协程安全的吗?
不是,可以看到map的状态是以hmap的flag字段来标识,在并发状态情况下,该字段不会被保护。会出现读写错误甚至是死锁的情况。
解决办法:
加锁,每次读写操作都加锁。但次锁的粒度是整个maps
使用sync.map。这个库的map已经包含读写锁。使用于大量读、少量写
2、申请的是什么类型的内存
堆内存。删除掉map中的元素不会释放内存,删除操作仅仅将对应的tophash[i]设置为empty,并非释放内存。若要释放内存只能等待指针无引用后被系统GC。
