
一、redis介绍
Redis(remote dictionary server)是一种NoSql类型数据库。
什么是NoSql数据库?
现在随着现阶段业务海量用户以及高并发业务,使得关系型数据库遇到很多瓶颈。例如:性能瓶颈,读写大量数据,使得磁盘IO性能低下;扩展性能差,在数据关系更复杂的情况下,关系型数据库扩展性变差,不再满足大规模集群。
若要解决这些问题,第一:减少磁盘访问的次数,可以考虑在内存加内存;第二:去除复杂的数据关系,越简单越好,可以考虑不存储关系,只存储数据
而NoSql(NotOnlySql)是关系型数据库的拓展。其特点是可扩容、可伸缩、大数据量下具有高性能、灵活的数据模型、高可用。Redis是NoSql的一种数据库。
Redis 是一种高性能键值对(key-value)数据库,可以用作数据库、缓存、消息中间件等
什么是键值对?
对于mysql关系型数据库的结构是:库-表-主键-信息
键值对是:K-V Key永远是string类型,而Value可以是第二章介绍的5种数据结构。
值得注意的是,redis只存储热点数据,而不是全部数据,基础数据信息还是存储在mysql使用。所以redis是和mysql配合使用的。
Redis特点:数据间没有必要的关联关系
- 内部采用单线程机制进行工作
- 高性能-内部
- 多数据类型支持
- 持久化支持,可以进行数据灾难恢复
应用场景:(后续我们详细介绍每种数据类型对应的场景)
- 为热点数据加速查询(主要场景)。热点商品,热点新闻等高访问信息
- 任务队列,如秒杀,抢购
- 即时信息查询,例如排行榜、在线人数等
- 时效性信息控制,如验证码
- 消息队列
- 分布式锁
二、redis五大数据类型
1、String
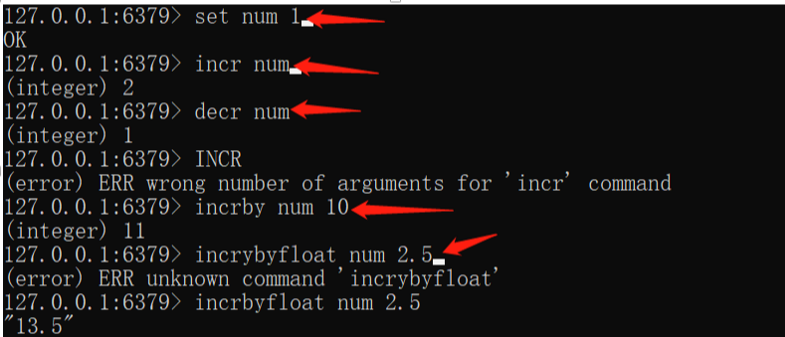
最简单的数据存储类型。一个存储空间只保存一个数据,若字符串是数字按照数字处理。redis所有的操作是原子性的,采用单线程处理所有的业务,命令是一个一个执行的,因此无需考虑高并发带来的数据影响
最大存储量:512MB
常用操作
1 | set key value //赋值 |
适用场景
1)投票的有效时长
可以指定数据的生命周期,来控制数据是什么时候失效,用过数据失效控制对应的业务行为,适用于具有时效性限定控制操作。
1 | setnx key seconds value // 设置key对应value值的有效时长是seconds |
2)大V用户信息的数据存储情况:粉丝数、博文数等
增加一个关注的粉丝,使用incr直接增加


redis用于各种数据结构和非结构高热度数据流访问。
这里说明一下数据库中热点数据key命名惯例:使用:分割数据层次

3)分布式锁
2、Hash
对存储的数据进行编组,典型的应用存储对象信息。一个存储空间可以保存多个键值对数据。底层是hash表的实现。
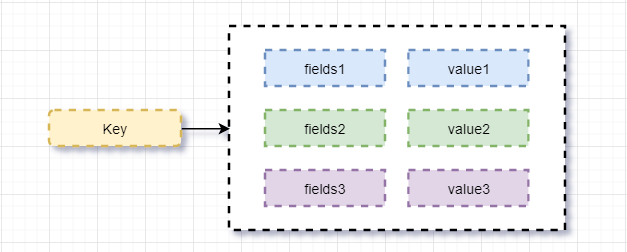
value值只存储字符串,每个hash可以存储2^32-1个键值对
常用操作
1 | hset key field value //为指定的key设置一个含有field、value的值 |
适用场景
1)电商网站购物车
购物车信息,可以容易增删改查,管理数量等
2)商家信息管理
应用于抢购,发放消费券(发完为止)等数据存储设计
3、List
存储多个数据,对数据进入存储空间的顺序要进行区分。数据主要要体现顺序,底层使用双向链表实现。
list保存的数据都是string类型的,最多有2^32-1个数据。list有索引的概念。
常用操作
1 | lpush key value1 value2 //给指定的key从头部开始添加value,如果key不存在则会自动创建 |
适用场景
1)朋友圈点赞,按照点赞顺序显示好友
应用于具有操作先后顺序的数据控制。
2)分页操作
通常第一页信息来自list,其他页信息来自数据库进行加载。
4、Set
存储大量数据,在查询方面提供更好的查询效率。与hash的存储结构相同,不同的是,只存储fileds值,不存储value值。Set不允许数据重复,也不能启动value功能
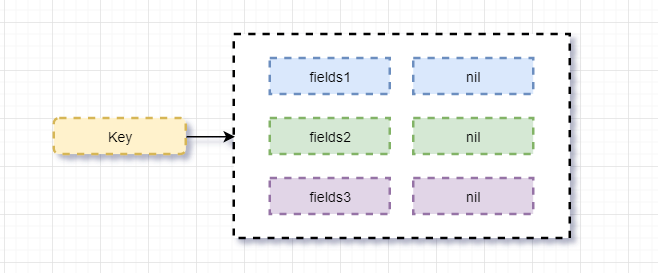
常用操作
1 | sadd key value1 value2 //给指定key中添加数据,元素不重复 |
适用场景
1)应用于同类消息的关联搜索
显示共同好友/关注(一度)
由用户A出发,获取共同好友B的好友列表(一度)
由用户A出发,获取共同好友B的购物清单/游戏充值列表(二度)
2)随机推荐类信息检索,例如推荐热点音乐、新闻等
3)不同类型不重复数据的合并操作,如权限配置
4)应用于同类型数据的快速去重,如访问量统计
5)基于黑名单与白名单设定服务控制(利用set的去重性)
5、Sorted_set
需求:数据排序有利于数据的展示,需要提供一种根据自身特征进行排序。在set的基础上添加score排序字段。score不存储数据,只用于排序。
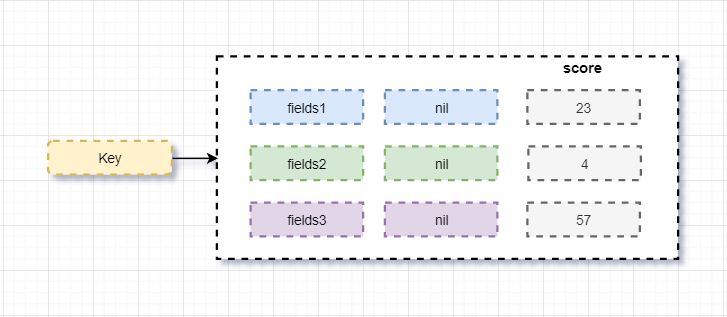
常用操作
1 | zadd key score name score2 name //将 score name 存储到指定的key中,如果有相同的name则覆盖之前的,返回值为新加入的元素,之前存在的不算 |
适用场景
1)为所有参与排名的资源建立排序依据。TOP10(歌曲,电影)
2)定时任务执行顺序管理或者过期管理。会员制度(月、季度、年)
(time获取系统当前时间)
总结

引用:
